Ragflow一个非常容易上手的RAG产品
Retrieval-Augmented Generation engine to unleash your full potential
1. Ragflow是什么
截取一段来自Ragflow官方的自我介绍: RAGFlow 是一款基于深度文档理解构建的开源 RAG(Retrieval-Augmented Generation)引擎。RAGFlow 可以为各种规模的企业及个人提供一套精简的 RAG 工作流程,结合大语言模型(LLM)针对用户各类不同的复杂格式数据提供可靠的问答以及有理有据的引用。
可以非常便捷的通过登录网址 https://demo.ragflow.io 试用 demo。最新的版本是V0.16.0,已经成功支持了火热全球的Deepseek模型。
1.1 主要功能
🍭 "Quality in, quality out"
- 基于深度文档理解,能够从各类复杂格式的非结构化数据中提取真知灼见。
- 真正在无限上下文(token)的场景下快速完成大海捞针测试。
🍱 基于模板的文本切片
- 不仅仅是智能,更重要的是可控可解释。
- 多种文本模板可供选择
🌱 有理有据、最大程度降低幻觉(hallucination)
- 文本切片过程可视化,支持手动调整。
- 有理有据:答案提供关键引用的快照并支持追根溯源。
🍔 兼容各类异构数据源
- 支持丰富的文件类型,包括 Word 文档、PPT、excel 表格、txt 文件、图片、PDF、影印件、复印件、结构化数据、网页等。
🛀 全程无忧、自动化的 RAG 工作流
- 全面优化的 RAG 工作流可以支持从个人应用乃至超大型企业的各类生态系统。
- 大语言模型 LLM 以及向量模型均支持配置。
- 基于多路召回、融合重排序。
- 提供易用的 API,可以轻松集成到各类企业系统。
1.2 系统架构
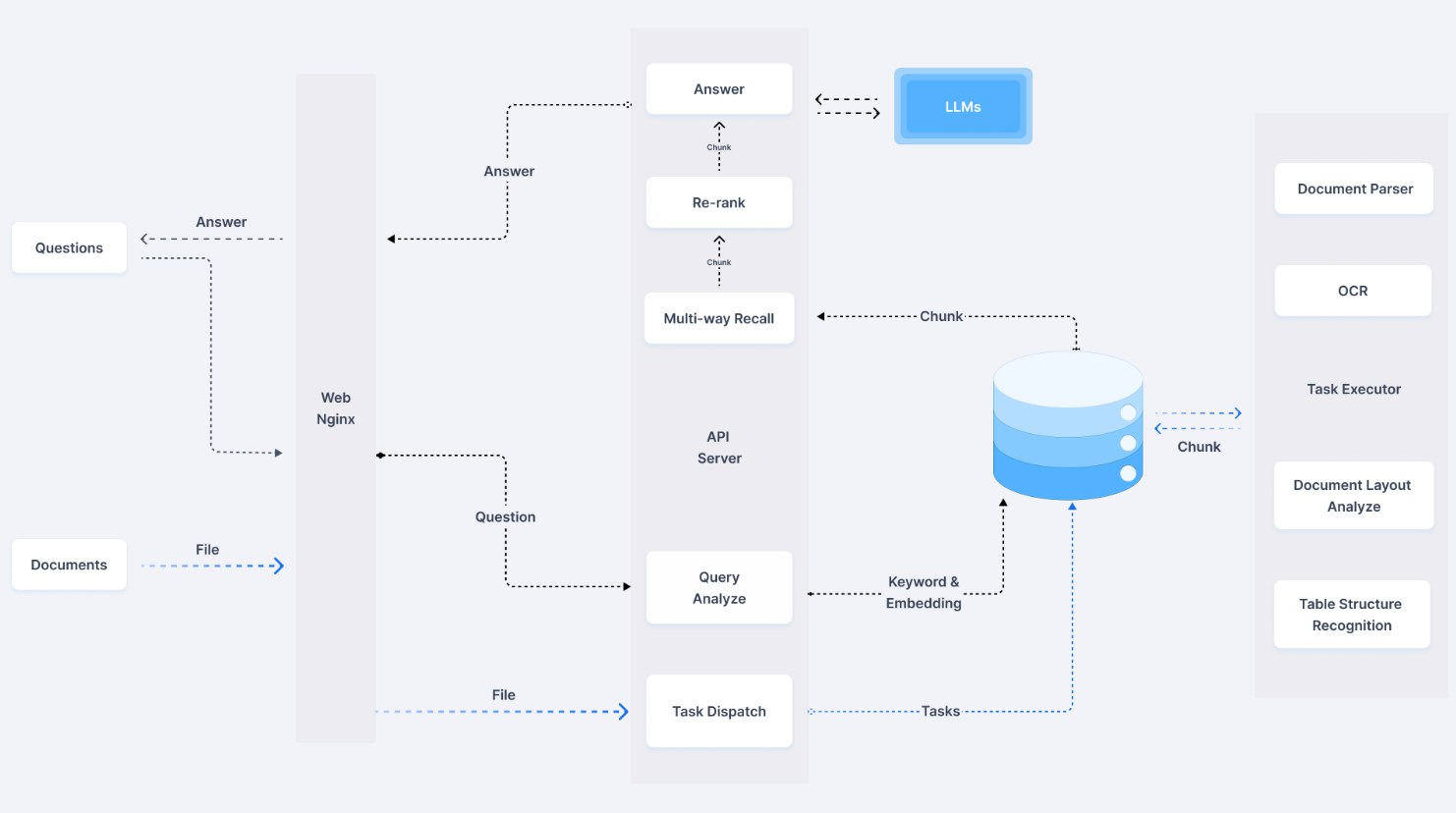 整体包含两条流:
整体包含两条流:
知识构建流:
- 文档解析:支持多种格式的文档,如PDF、Word、HTML等
- 多样数据识别:包括 OCR 图片识别、文档布局分析、表结构识别
- 文本切片:基于模板的灵活切片策略
- 向量化:将文本转换为向量表示
- 索引构建:创建高效的检索索引
问答检索增强流:
- 查询处理:对用户输入进行预处理和理解
- 多路召回:使用多种策略检索相关信息
- 重排序:对检索结果进行精确排序
- LLM生成:利用大语言模型生成最终答案
- 引用追踪:提供答案的来源和依据
2. Ragflow本地部署
因为我使用了Docker Desktop,关于确保 vm.max_map_count 不小于 262144的过程就可以省略不设置。
📝 部署前提条件
前提条件
CPU >= 4 核
RAM >= 16 GB
Disk >= 50 GB
Docker >= 24.0.0 & Docker Compose >= v2.26.1
如果你并没有在本机安装 Docker(Windows、Mac,或者 Linux), 可以参考文档 Install Docker Engine 自行安装。
项目本身的大小在9GB左右。只是对内存有一定的要求。我曾尝试在不足要求的情况下运行,会出现在文档解析的过程中ElasticSearch报错,即使改成Infinity模式,对于页数较多的文件也会报错。
2.1 克隆仓库:
$ git clone https://github.com/infiniflow/ragflow.git运行以下命令会自动下载 RAGFlow slim Docker 镜像
v0.16.0-slim。请参考下表查看不同 Docker 发行版的描述。如需下载不同于v0.16.0-slim的 Docker 镜像,请在运行docker compose启动服务之前先更新 docker/.env 文件内的RAGFLOW_IMAGE变量。比如,你可以通过设置RAGFLOW_IMAGE=infiniflow/ragflow:v0.16.0来下载 RAGFlow 镜像的v0.16.0完整发行版。
$ cd ragflow
$ docker compose -f docker/docker-compose.yml up -d| RAGFlow image tag | Image size (GB) | Has embedding models? | Stable? |
|---|---|---|---|
| v0.16.0 | ≈9 | ✔️ | Stable release |
| v0.16.0-slim | ≈2 | ❌ | Stable release |
| nightly | ≈9 | ✔️ | Unstable nightly build |
| nightly-slim | ≈2 | ❌ | Unstable nightly build |
一开始我下了默认的slim版本,没有embedding,还以为需要从huggingface引入才可以。.env文件中还可以设置上传文件大小的限制。目前最大的是128MB。
2.2 服务器启动
上述compose命令拉取完成之后就会自动启动服务器,在docker的log里面也可以看到。在有梯子情况下没有出现无法拉取的错误。
成功后再次确认服务器状态:
$ docker logs -f ragflow-server出现以下界面提示说明服务器启动成功:
____ ___ ______ ______ __
/ __ \ / | / ____// ____// /____ _ __
/ /_/ // /| | / / __ / /_ / // __ \| | /| / /
/ _, _// ___ |/ /_/ // __/ / // /_/ /| |/ |/ /
/_/ |_|/_/ |_|\____//_/ /_/ \____/ |__/|__/
* Running on all addresses (0.0.0.0)
* Running on http://127.0.0.1:9380
* Running on http://x.x.x.x:9380
INFO:werkzeug:Press CTRL+C to quit可能是版本的边喝,实际running并没有上面这样标准的三行地址,实际可以访问的地址是localhost:80。
如果您跳过这一步系统确认步骤就登录 RAGFlow,你的浏览器有可能会提示
network anormal或网络异常,因为 RAGFlow 可能并未完全启动成功。
3. Ragflow使用体验
3.1 知识解析
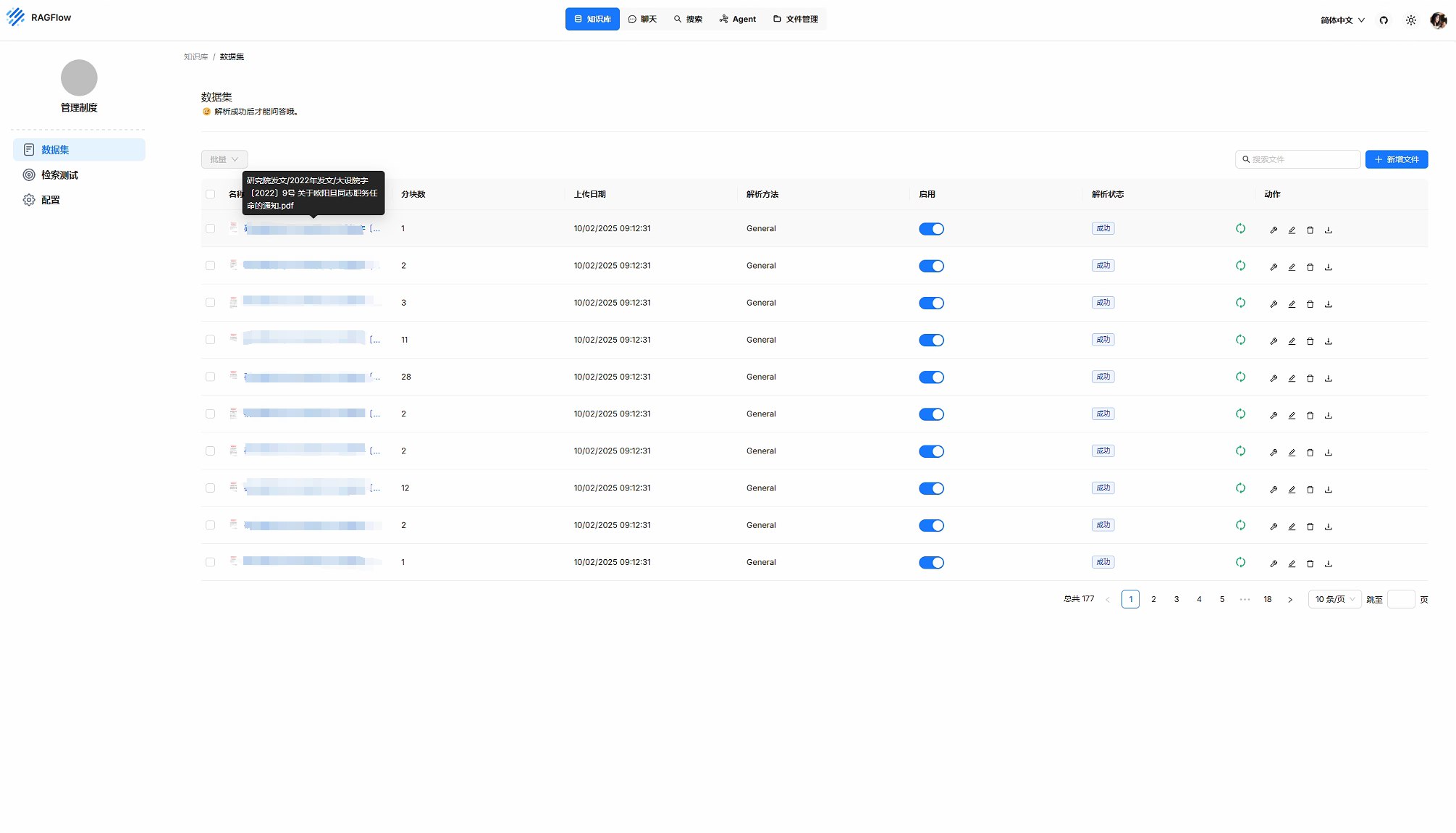 使用RAGFlow的核心是将你所有用的资料、文档、数据上传并成功被Embedding模型解析。
使用RAGFlow的核心是将你所有用的资料、文档、数据上传并成功被Embedding模型解析。
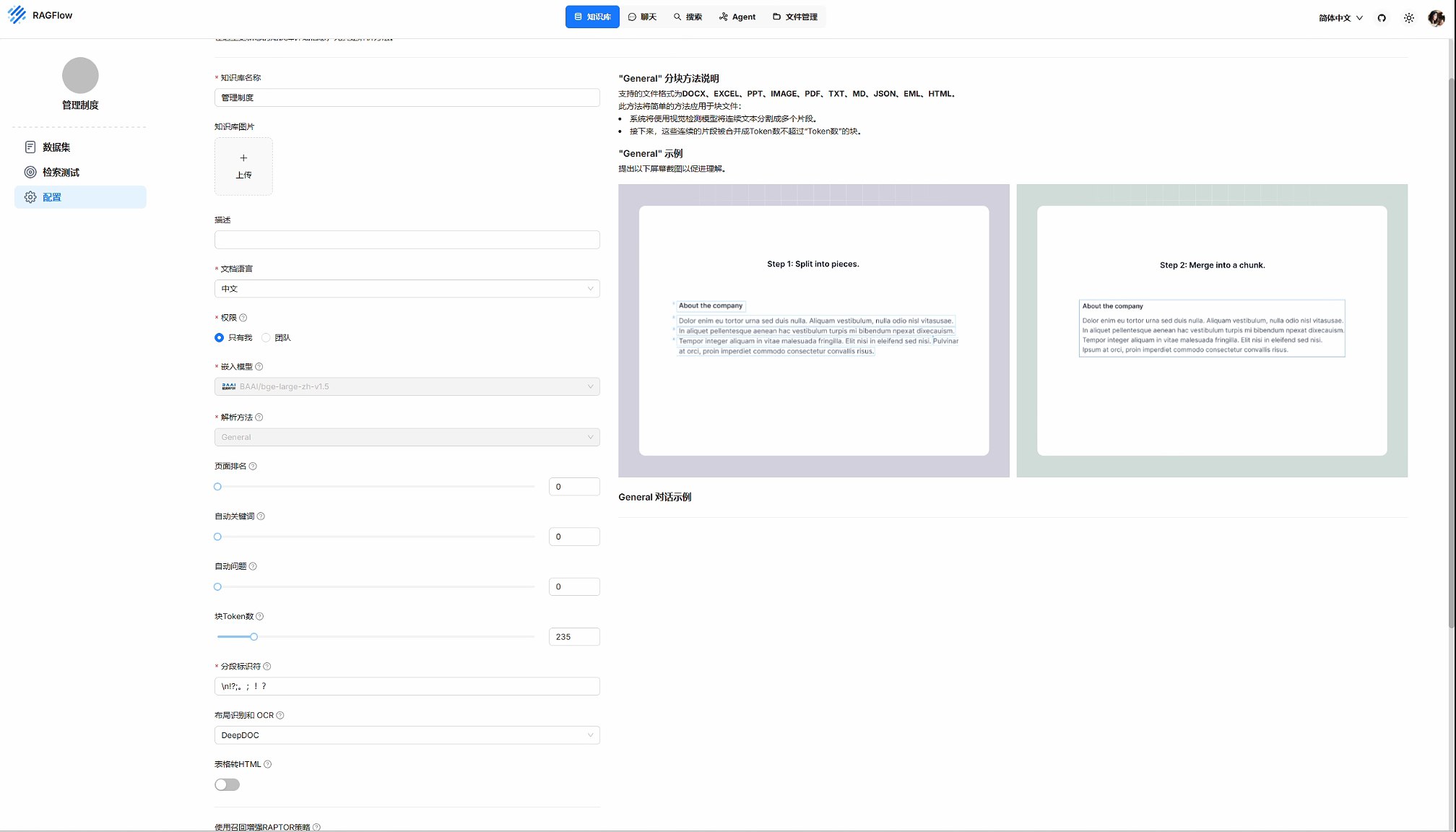 在知识库的配置中,可以通过配置嵌入模型、解析方法、页面排名、块Token数、局部识别、召回增强等参数来优化解析的准确性。其中解析方法主要包括:
在知识库的配置中,可以通过配置嵌入模型、解析方法、页面排名、块Token数、局部识别、召回增强等参数来优化解析的准确性。其中解析方法主要包括:
General: 支持的文件格式为DOCX、EXCEL、PPT、IMAGE、PDF、TXT、MD、JSON、EML、HTML。此方法将简单的方法应用于块文件:系统将使用视觉检测模型将连续文本分割成多个片段。这些连续的片段被合并成Token数不超过“Token数”的块。
Q&A:此块方法支持 excel 和 csv/txt 文件格式。如果文件是 excel 格式,则应由两个列组成 没有标题:一个提出问题,另一个用于答案, 答案列之前的问题列。多张纸是 只要列正确结构,就可以接受。如果文件是 csv/txt 格式 以 UTF-8 编码且用 TAB 作分开问题和答案的定界符。 未能遵循上述规则的文本行将被忽略,并且 每个问答对将被认为是一个独特的部分。
Manual: 仅支持PDF。我们假设手册具有分层部分结构。 我们使用最低的部分标题作为对文档进行切片的枢轴。 因此,同一部分中的图和表不会被分割,并且块大小可能会很大。
Table: 支持EXCEL和CSV/TXT格式文件。 对于 csv 或 txt 文件,列之间的分隔符为 TAB。 第一行必须是列标题。 列标题必须是有意义的术语,以便我们的大语言模型能够理解。 列举一些同义词时最好使用斜杠'/'来分隔,甚至更好 使用方括号枚举值,例如 'gender/sex(male,female)'.
还有Paper、Book、Law等格式类文件模式。经过测试,以上几种模式对于现有的一些数据、文件都可以比较好的解析。但是每一个知识库需要固定一种解析方法,所以对于不同类型的数据,需要分别建立不同的知识库。
Ragflow本身支持多类异构数据源,包括 Word 文档、PPT、excel 表格、txt 文件、图片、PDF、影印件、复印件、结构化数据、网页等。
3.2 对话聊天
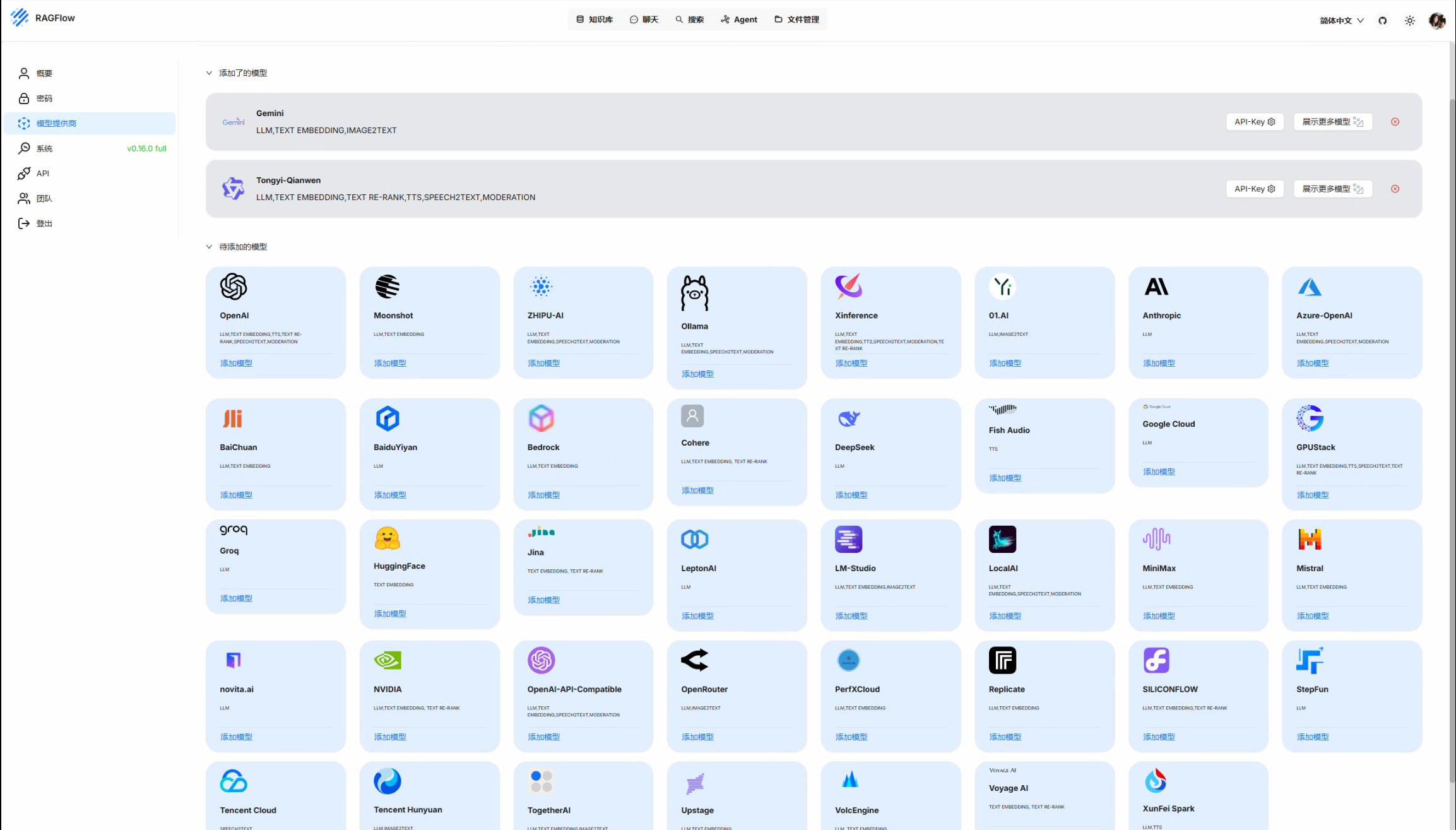
Ragflow打通了市面上主流啊大模型api接口,常用的OpenAI、Gemini、DeepSeek、Claude、Huggingface等都可以在这里接入使用。
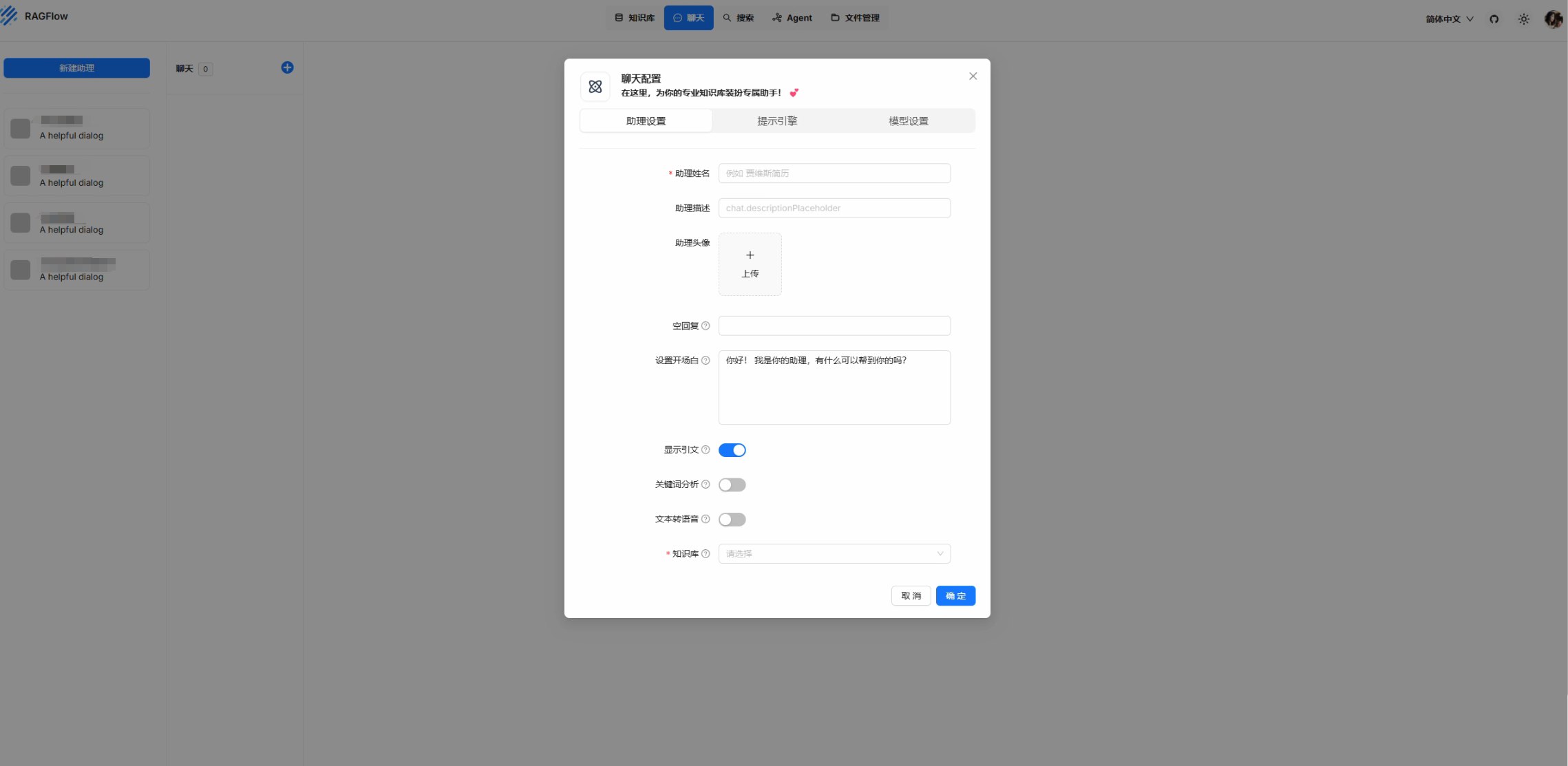
在对话聊天中通过新建助力-->选择模型、知识库-->选择关键词、知识图片、Rerank模型-->设置模型温度、最大token数之后就可以开始对话聊天了。每次对话可以查看检索的内容和对话的耗时,Embedding和答案的生成是耗时较长的,如果开启Rerank模型,耗时会进一步增加。
Details
耗时 Total: 15163.9ms Check LLM: 1.5ms Create retriever: 0.8ms Bind embedding: 5311.7ms Bind LLM: 28.9ms Tune question: 1530.8ms Bind reranker: 0.0ms Generate keyword: 1156.1ms Retrieval: 1306.1ms Generate answer: 5828.0ms
3.3 Agents
RAGFlow还有一个很好用的功能是Agents。与Dify类似,有一些基本的功能组件,一些插件,通过拖拽的方式可以实现智能体的构建。比如网页的所搜、信息的检索、天气的查询等等。并且可以加入本地的知识库实现信息检索效果的增强。
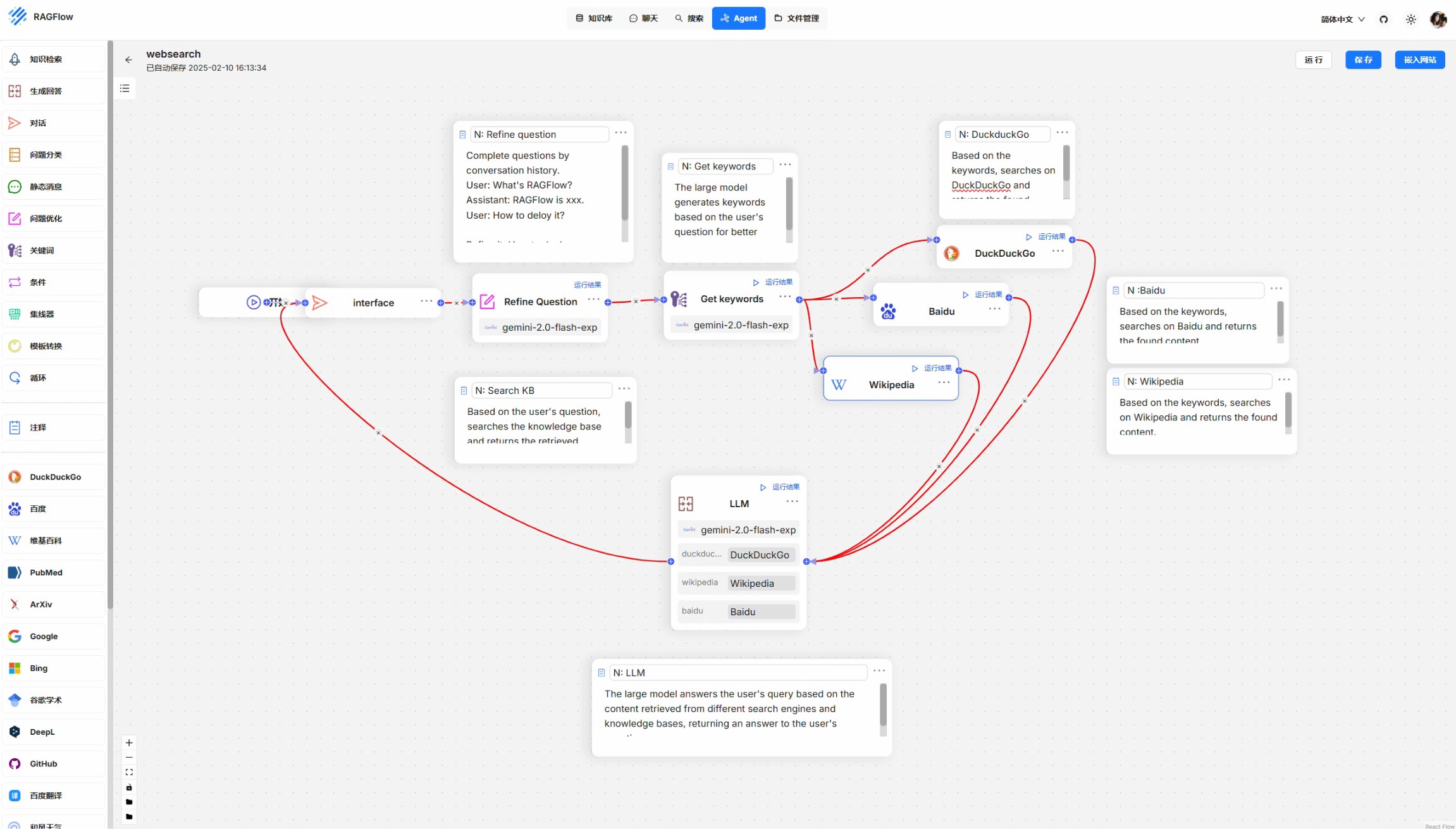
Ragflow的Agents是支持连续对话的,所有所有节点的连线可以闭环连接,实现连续对话。
插件部分目前主要是外部的搜索以及几个财经资讯信息的获取,比如问财、金十、东方财富等,可见团队在开发的初衷是基于以上渠道获取的咨询进行检索,辅助政策分析或者投资分析。此外还有场景的PubMed、谷歌学术、ArXiv等学术检索,对于论文的粗读、检索有比较好的帮助。
节点部分暂时没有看到开放可编程的节点。
4. 总结及展望
对比之前接触到的几个RAG产品,比如AnythingLLM、Open WebUI等,在检索的效果、模型的支持、功能设置上都更加易用。迭代更新的速度也比较好。成熟的V0.16.0版本也采用了社群的模式,有一些简单的使用问题可以在群内得到快速的解答。同时,此版本的Ragflow也提供了非常全面的API接口。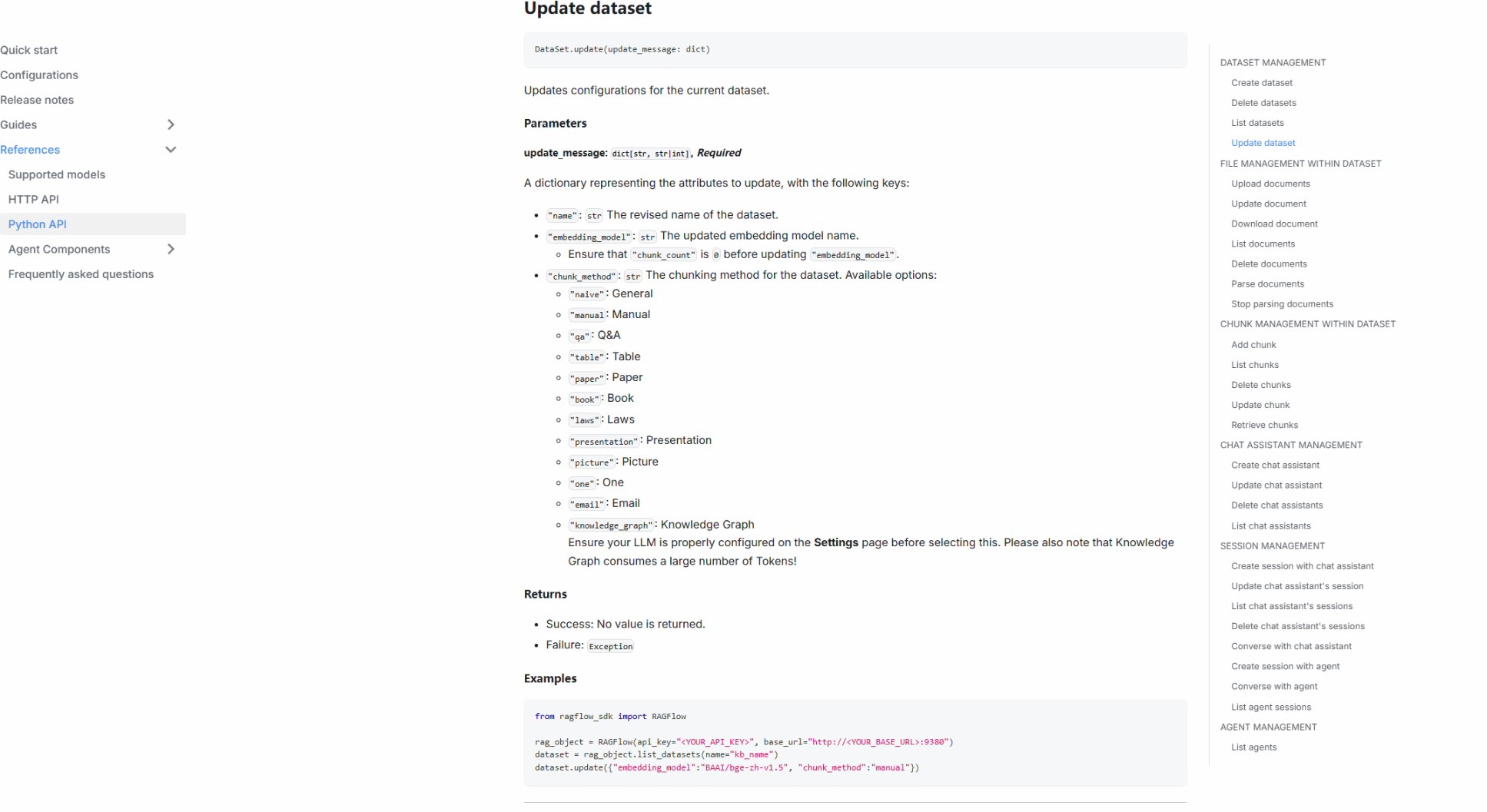 条件允许的情况,可以设计自己的项目页面,通过保留文档解析、对话等功能,实现自己的RAG产品。此外,已经配置好的对话、Agents也提供了全屏嵌入模式的API。
条件允许的情况,可以设计自己的项目页面,通过保留文档解析、对话等功能,实现自己的RAG产品。此外,已经配置好的对话、Agents也提供了全屏嵌入模式的API。
基于RAGFlow的应用场景构想
- 做一个Digital Twin。将自己每天的日记、图片、声音、定位等信息都形成知识库提供给它。模型就了解了你所有的历史,你可以回顾自己的过往,记录自己的人生,素材充足的话还可以用来撰写自己的故事。
功能的不足
- 在对话环节,部门模型的api应该具备联网搜索的能力,目前还没有办法实现。
- Agents的插件还比较少,希望未来可以有更多的插件支持。